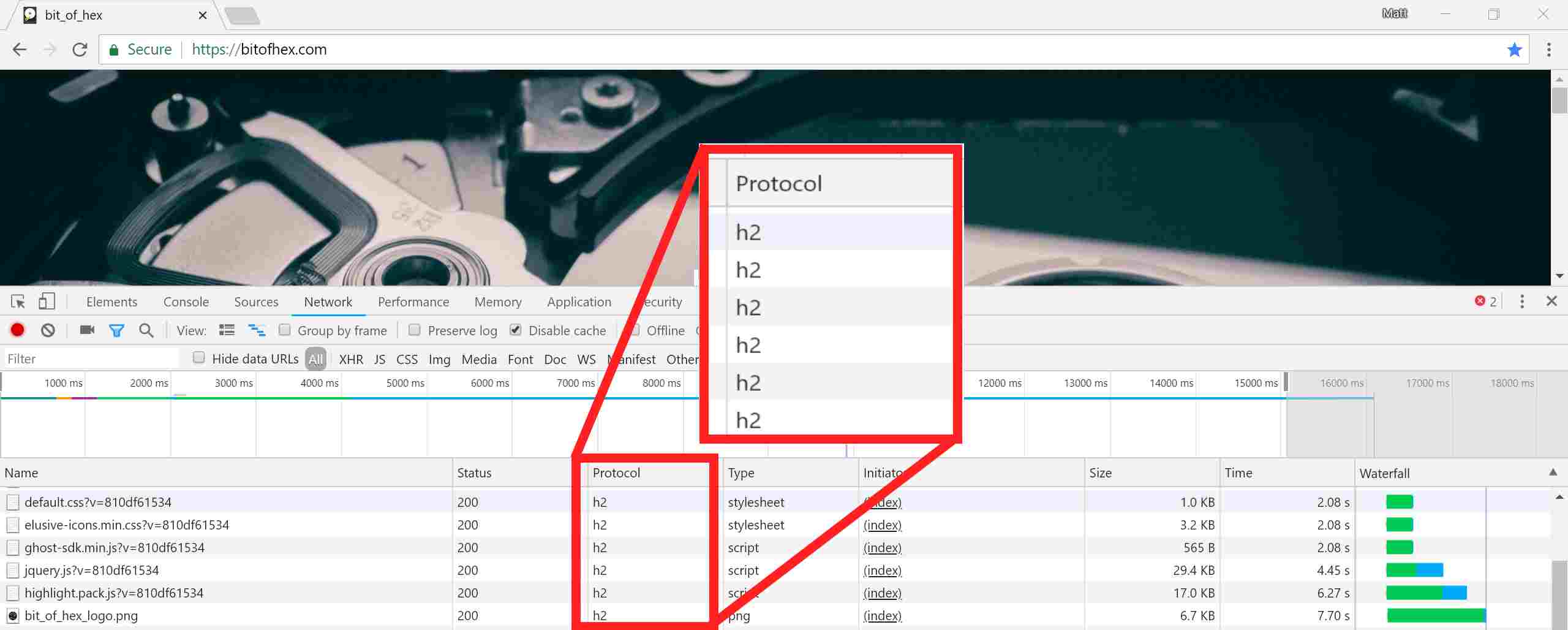
HTTP/2 is fundamentally different from HTTP/1.x; but it is not some edge-case of internet traffic. Figures that I found from April 2016 indicated it was 68% of web-traffic. It is supported by the major browsers, and even the lowly bit_of_hex blog is sent via HTTP/2. To check, the browsers generally identify HTTP/2 traffic as ‘h2’ in their developer tools.
HTTP/2 is a binary protocol (as opposed to HTTP/1.1) and based around ‘frames’ which include types such as HEADERS, DATA, SETTINGS, and WINDOW_UPDATE. Communication occurs over a single TCP connection and may include a number of bidirectional ‘streams’. Each uniquely identified stream can carry bidirectional ‘messages’. Streams operate independently so a stalled request does not affect other request/responses. Apart from RFC 7540 a great resource is Ilya Grigorik’s book High Performance Browser Networking published by O’Reilly Media.
I’ve been examining the mechanics of the HTTP/2 protocol. Previously, I identified Chrome incorrectly tags HTTP/2 server response headers as ‘HTTP/1.1’ when saving data to the disk cache. However, another particular aspect caught my attention: HTTP/2 push. This functionality in HTTP/2 seems quite interesting. The RFC describes it as follows:
HTTP/2 adds a new interaction mode whereby a server can push responses to a client…Server push allows a server to speculatively send data to a client that the server anticipates the client will need, trading off some network usage against a potential latency gain.
So essentially, a server can ‘push’ data to a client without a formal ‘request’? Of course, the evil part of me said, ‘Muhahah, I could send an evil file!” Then the part of me that might be in court said ‘Hang on, what happens if I push something to the client? Where do it go?’
I want to try to answer the following questions:
- What does the HTTP/2 push request/response look like from both the client and server?
- How does the browser handle HTTP/2 pushed data before it is actually used by the web-page?
- Could a malicious server push illicit/unwanted data to the browser disk cache through HTTP/2 server push?
- Can host or network forensics identify HTTP/2 pushed data?
Forensic Testing of HTTP/2 Push
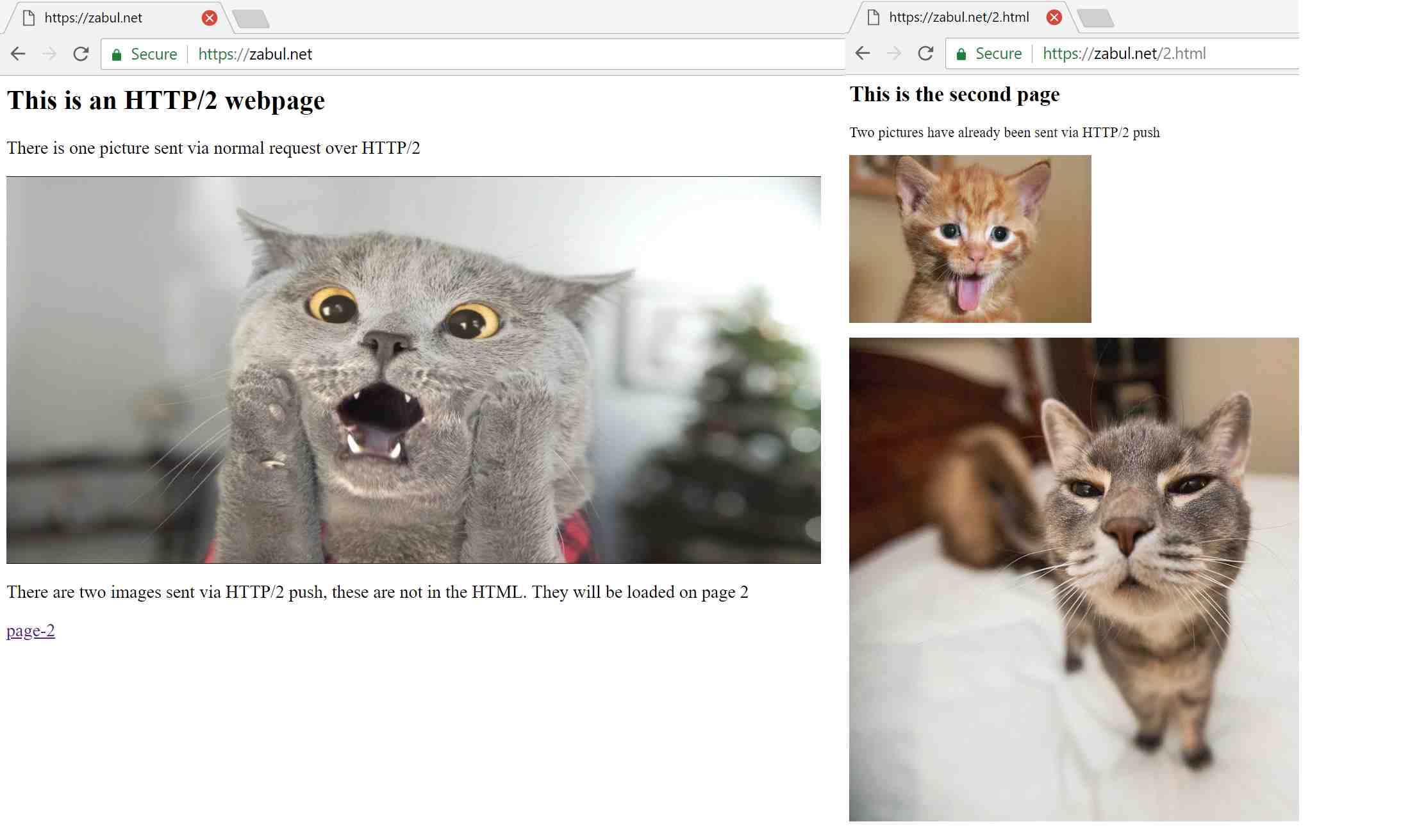
For testing, I set up a simple two-page website (https://zabul.net - thanks for cheap domain names!) which delivered content over HTTP/2. The first page displayed one image file but actually pushed two additional image files. The second page used these ‘pushed’ files. Usually, the pushed content wouldn’t be divided between multiple pages; however, this is a good way to experiment with HTTP/2 push under controlled conditions. Doing this testing also allowed me to demonstrate my highly (un)skilled HTML coding.1
The testing setup was as follows:
- The web server was run through a Digital Ocean droplet with Ubuntu 18.03, Ngnix 1.14.0 and Let’s Encrypt TLS certificate. The client was a virtual machine running Windows 10x64 (1803) with Chrome 67.0.3369.99 (x64).
- Page 1 of the web server sends one picture ‘normally’ called
cat_no_push.jpgand two pictures via HTTP/2 push, calledcat-pushed_1.jpgandcat-pushed_2.jpg. - Page 2 of the web server then loads the two pushed files from Page 1.
HTTP/2 Push Mechanics
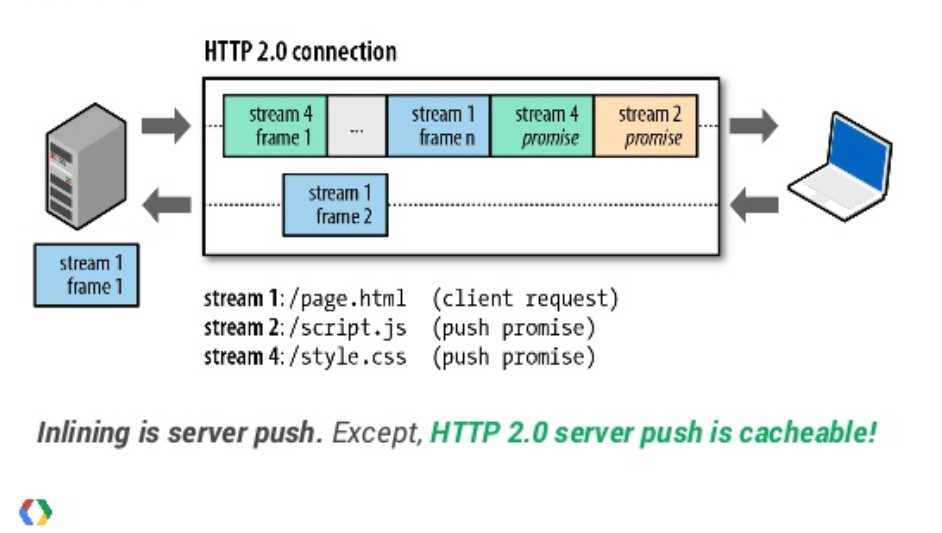
A HTTP/2 push is initiated through a PUSH_PROMISE frame which identifies the headers of the data to be pushed. If accepted, the server can then push the data in a separate stream. Chrome gives a user complete insight into the HTTP/2 requests under chrome://net-internals. The simplest diagram I found displaying the mechanics of HTTP/2 push was from a presentation by Ilya Grigorik here.
So let’s dive in and take a look…
What does the HTTP/2 push request/response look like from both the client and server?
From the web-server the Nginx logs look as expected. When ‘Page 1’ loads we have four entries:
203.0.113.1 - - [30/Jun/2018:03:56:38 +0000] "GET / HTTP/2.0" 200 246 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
203.0.113.1 - - [30/Jun/2018:03:56:38 +0000] "GET /cat-pushed_1.jpg HTTP/2.0" 200 5919 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
203.0.113.1 - - [30/Jun/2018:03:56:38 +0000] "GET /cat-pushed_2.jpg HTTP/2.0" 200 94985 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
203.0.113.1 - - [30/Jun/2018:03:56:38 +0000] "GET /cat_no_push.jpg HTTP/2.0" 200 104154 "https://zabul.net/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
Some observations of the logs from page 1:
- There is nothing identifiable to indicate that the data has been ‘pushed’ (apart from the file names);
- The logs note it was sent via ‘HTTP/2.0’ so an understanding of the RFC would need to be required to know that server push exists; and
- The pushed JPEG files were sent prior to the single required file (which is part of the push mechanics).
When page 2 loads we have the following single entry is added to the logs:
203.0.113.1 - - [30/Jun/2018:03:59:00 +0000] "GET /2.html HTTP/2.0" 200 173 "https://zabul.net/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
From this entry:
- An astute observer looking in isolation might wonder where the JPEG files were; however, this can be matched with the immediately preceding log entries; and
- There is still nothing (as expected) to indicate data was pushed to the client.
Lastly the Nginx configuration file has the complete picture with lines 7 & 8 commencing with http2_push identifying the pushed data. 2
server {
listen 443 ssl http2 default_server;
listen [::]:443 http2 default_server;
root /var/www/html;
server_name zabul.net;
location = /index.html {
http2_push /cat-pushed_1.jpg;
http2_push /cat-pushed_2.jpg;
}
ssl_certificate /etc/letsencrypt/live/zabul.net/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/zabul.net/privkey.pem; # managed by Certbot
ssl_dhparam /etc/letsencrypt/live/zabul.net/dhparam.pem;
}
server {
listen 80;
listen [::]:80;
server_name zabul.net;
return 301 https://$server_name$request_uri;
}
From the client side on Chrome, it gets a little better. Chrome provides a great array of tools to inspect web-pages and traffic. One tool is chrome://net-internals which allows HTTP/2 traffic to be dissected.
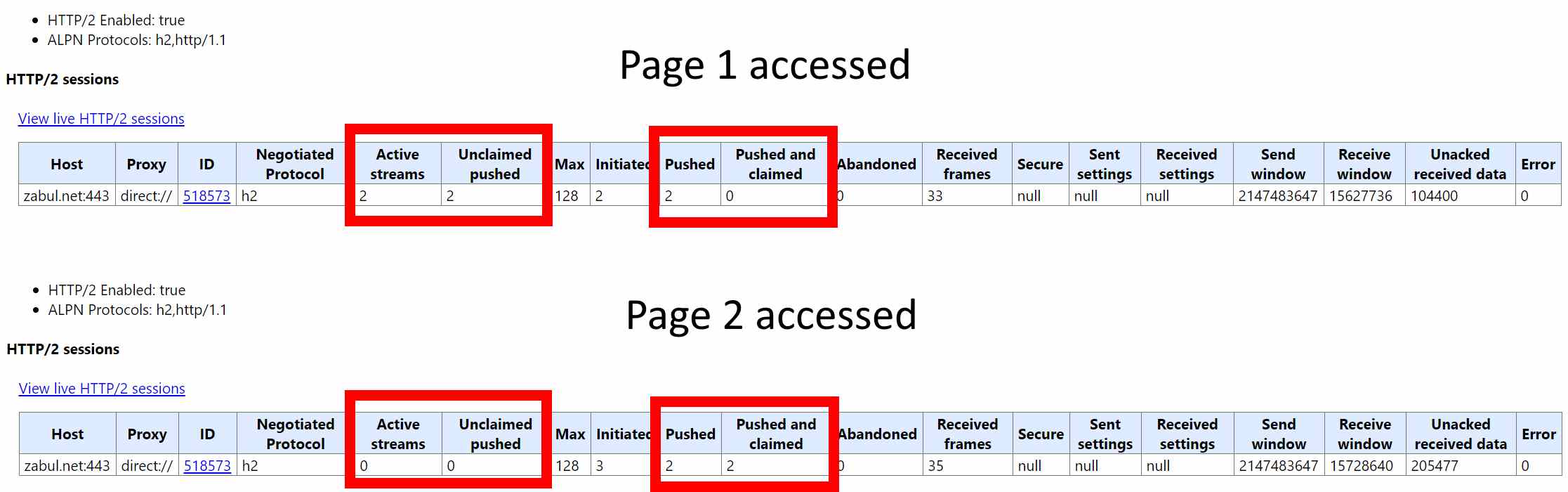
When loading page 1, Chrome identifies ‘Pushed’ as ‘2’ and ‘Unclaimed push’ as ‘2’. Clicking through to page 2 indicates that ‘Pushed’ remains ‘2’ and ‘Pushed and claimed’ is now ‘2’.
Chrome also provides the ability to observe the raw HTTP/2 headers which clearly identify the PUSH_PROMISE traffic is sent prior to the image used on page 1:
896: HTTP2_SESSION
zabul.net:443 (DIRECT)
Start Time: 2018-06-30 13:57:03.177
t=348075 [st= 0] +HTTP2_SESSION [dt=?]
--> host = "zabul.net:443"
--> proxy = "DIRECT"
t=348075 [st= 0] HTTP2_SESSION_INITIALIZED
--> protocol = "h2"
--> source_dependency = 894 (SOCKET)
***snipped***
t=348368 [st= 293] HTTP2_SESSION_RECV_PUSH_PROMISE
--> :method: GET
:path: /cat-pushed_1.jpg
:scheme: https
:authority: zabul.net
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36
--> id = 1
--> promised_stream_id = 2
t=348368 [st= 293] HTTP2_STREAM_SEND_PRIORITY
--> exclusive = true
--> parent_stream_id = 1
--> stream_id = 2
--> weight = 110
t=348368 [st= 293] HTTP2_SESSION_RECV_PUSH_PROMISE
--> :method: GET
:path: /cat-pushed_2.jpg
:scheme: https
:authority: zabul.net
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36
--> id = 1
--> promised_stream_id = 4
t=348368 [st= 293] HTTP2_STREAM_SEND_PRIORITY
--> exclusive = true
--> parent_stream_id = 2
--> stream_id = 4
--> weight = 110
***snipped***
t=348395 [st= 320] HTTP2_SESSION_SEND_HEADERS
--> exclusive = true
--> fin = true
--> has_priority = true
--> :method: GET
:authority: zabul.net
:scheme: https
:path: /cat_no_push.jpg
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36
accept: image/webp,image/apng,image/*,*/*;q=0.8
referer: https://zabul.net/
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9
--> parent_stream_id = 0
--> source_dependency = 900 (HTTP_STREAM_JOB)
--> stream_id = 3
--> weight = 147How does the browser handle HTTP/2 pushed data before it is actually used by the web-page?
This question proved to be more difficult to determine. Initially I hypothesised pushed data would be saved to the disk cache before it was used (i.e. when page 1 was accessed). However, testing with Nirsoft and Hindsight indicated the pushed JPEG files were saved at the time Page 2 was accessed.
Page 1 cache logs were as follows:

Page 2 cache logs were as follows:

One small indicator is that the server response headers will note the date and time it was pushed to the client, so in my case, where there is a significant difference between accessing page 1 and page 2, the pushed data can be identified as anomalous.
So, instead of the disk cache forensic tools, I tried to identify if a temporary file was created. Using SysInternals Process Monitor and Regshot I monitored changes to the file system and registry but couldn’t identify any data of interest.
Lastly, I undertook some Googling. Eventually I found an email thread between Chromium developers which seemed to explain what was happening. This dated 2006 thread discussing HTTP/2 push confirmed the push resource sits in the memory cache rather than written to the disk cache. Here two Chromium developers explain the mechanics as follows:
The net stack is structured so that the the (sic) cache transaction layer generates network transactions when needed. For server push, the layering means that when pushed resources arrive there isn’t an obvious way for the net layer to interact with the cache. When the page “uses” the a (sic) pushed resource, the net layer intercepts the request and supplies the pushed resource from memory. This is transparent to the cache layer, so the resource will be stored in the http cache as usual as part of the cache transaction.
and
Pushed streams sit deep in the bowels of the //net stack, in the browser process, in memory, as part of SpdySession. When PUSH streams come along on a session, we drain the frame from the SpdySession (because we have to, to avoid HOL), and drop it into a SpdyStream. That SpdyStream will later (potentially) be claimed by a request, at which point, we replay the frames from the SpdyStream
So, while difficult to confirm from a forensic perspective, the pushed data resides in memory until claimed. While I’m no software developer, if needed, the push mechanics can be reviewed in the Chromium source code. I’m not entirely comfortable with my own explanation, mainly due to the lack of contemporary information. So if there are better resources or testing available then please let me know.
Could a malicious server push illicit/unwanted data to the browser disk cache through HTTP/2 server push?
From my testing the answer is ‘no’. Based on the comments from Chrome developers this scenario was considered. If malicious data was pushed to the disk and then Chrome identified the site to be malicious and blocked it, the data would still have been pushed - which is not a good security outcome. Chrome developers also envisaged a problem where pushed data could potentially be continually pushed to disk even if the page was canceled.
Can host or network forensics identify HTTP/2 pushed data?
Yes and no.
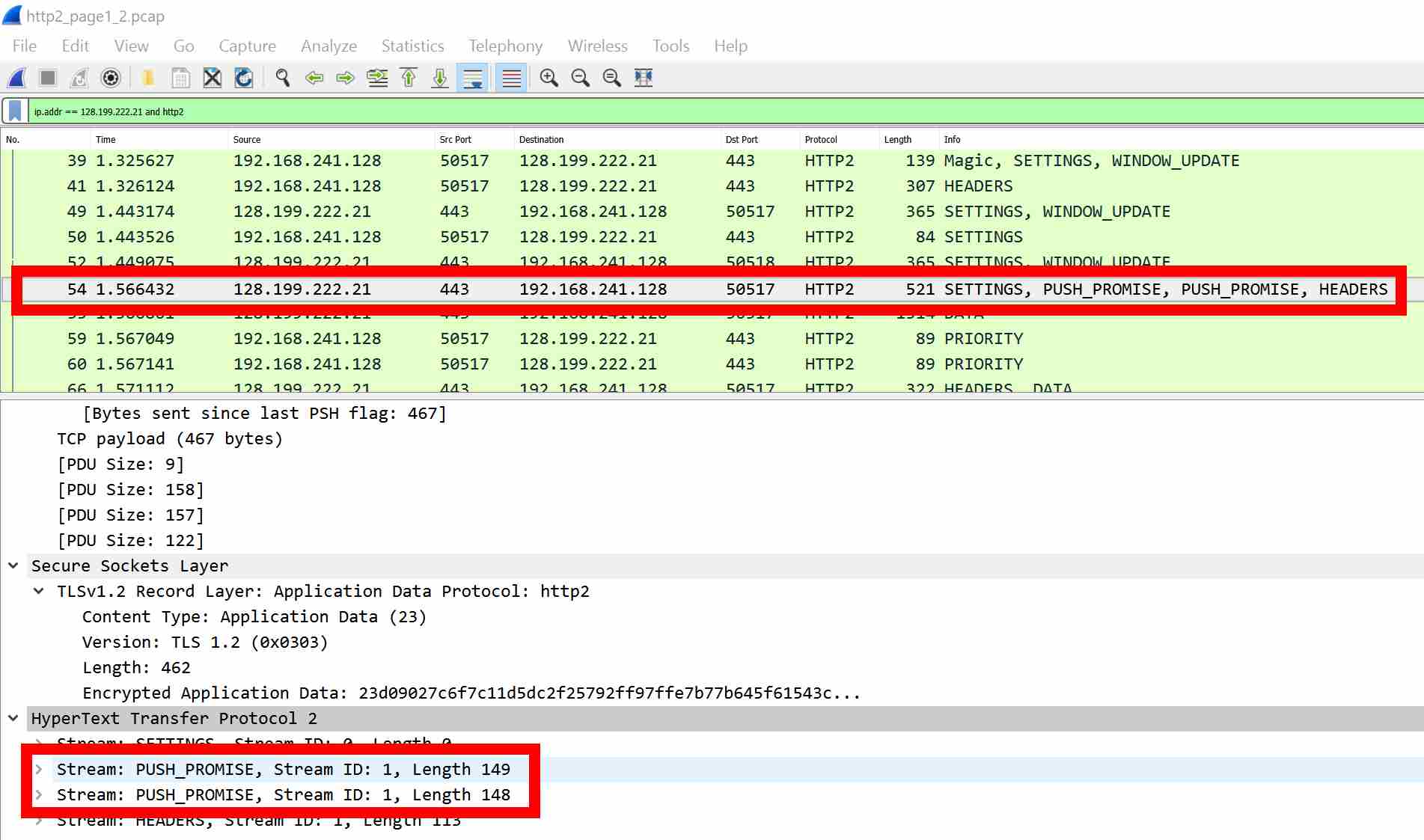
Inspection of the network traffic will clearly identify the PUSH_PROMISE data either in the Chrome net-internal logs or with Wireshark. Note you’ll need to dump the TLS session keys to decrypt the data.
Here in Wireshark the PUSH_PROMISE data is observed:
Here the actual pushed JPEG can be carved from the packet capture:
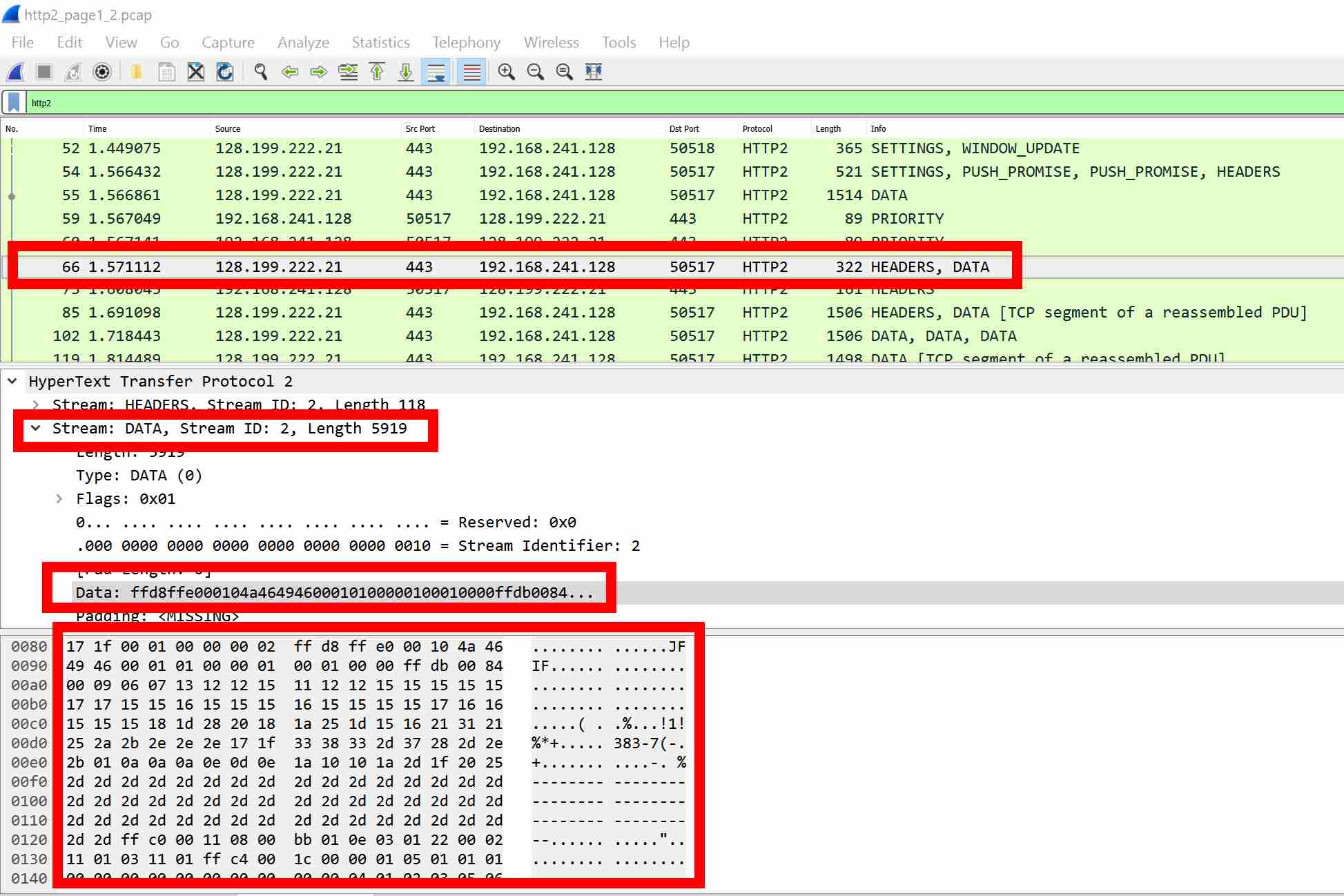
Host forensics is much more difficult to identify; but it actually might not be necessary. As the pushed data is not written to the disk cache until it is actually used by Chrome, there is no likely situation where there would be unused disk artefacts left.
However, if you were keen to try and identify HTTP/2 pushed data consider the following:
- Read my previous post here to be aware Chrome incorrectly labels HTTP/2 traffic as HTTP/1.1. Therefore, the cached data will not be explicitly identifiable as HTTP/2 (until this bug is fixed by Google); and
- Look for differences between cache artefact date and time and server response header date and time which may indicate the data was pushed. However, given most pushed data will likely be used on the same page the time difference (if any) might be negligible.
Conclusion
Ultimately, while there is no ‘forensic issue’ with HTTP/2 push and Chrome, it is useful to know and understand how HTTP/2 push mechanics work.3 It is also useful to know how Chrome (correctly) handles pushed data if you ever get asked those famous ‘so is it possible…’ questions by a lawyer.
This is definitely not the ‘be-all-and-end-all’ of HTTP/2 push. If you have any questions or comments, please feel free to contact me at [email protected] or on Twitter at @mattnotmax.
-
I won’t be applying to any web-site design jobs anytime soon. ↩︎
-
There are in-line ways to push data; however, they have not been tested at this time. ↩︎
-
As always there are limitations: Only Chrome was tested due to it having such a large market share and great developer tools that allowed inspection of the HTTP/2 traffic and there are multiple ways to implement push at the server end: either within the global configuration file or via the web-pages themselves. Only the configuration file was tested. ↩︎